
最後更新時間: 2025 年 04 月 19 日
最近在上LLM線上課 來分享我所學到的 LangChain LangChian是把ChatGPT API 轉換為物件導向的形式來使用我所學到 LangChain 的五個方法 : Prompt Template / LLMChain / OutputParser / Agent / ConversationChain
這些知識分享和所學都是來自Tibame緯育大型語言模型LLM企業應用開發實戰班,這是一個直播線上課程,內容會提及Langchian和向量資料庫,推薦給大家! (https://www.tibame.com/program/llm)
Prompt Template
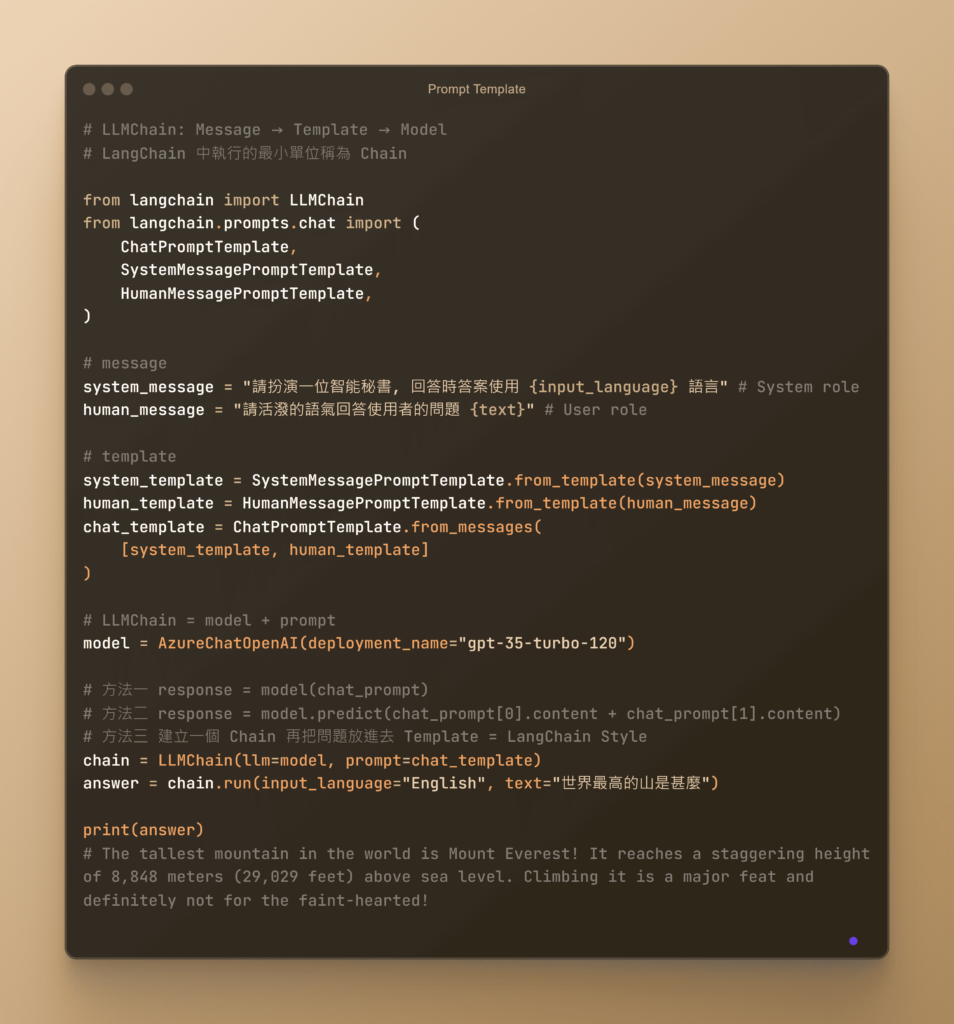
介紹: Prompt Template 是 LangChain 中的重要概念之一,用來定義和格式化我們發送給模型的訊息。這些模板能夠幫助開發者建立可重複使用的格式,確保每次與模型的互動都遵循特定的結構。
系統模板(System Template): 這個模板用來設置對話的背景和規則。換句話說,它包含了模型在回答問題時應遵循的指示或角色。
人類模板(Human Template): 這個模板定義了用戶的輸入訊息,這些訊息是模型需要回應的主要內容,通常包括用戶的問題或需求。
應用:
- 多輪對話: 在多次交互中保持一致性,確保模型能夠連貫地理解和回應上下文。
- 生成提示: 根據用戶的行為和輸入生成提示,提供更個性化的體驗。
LLMChain
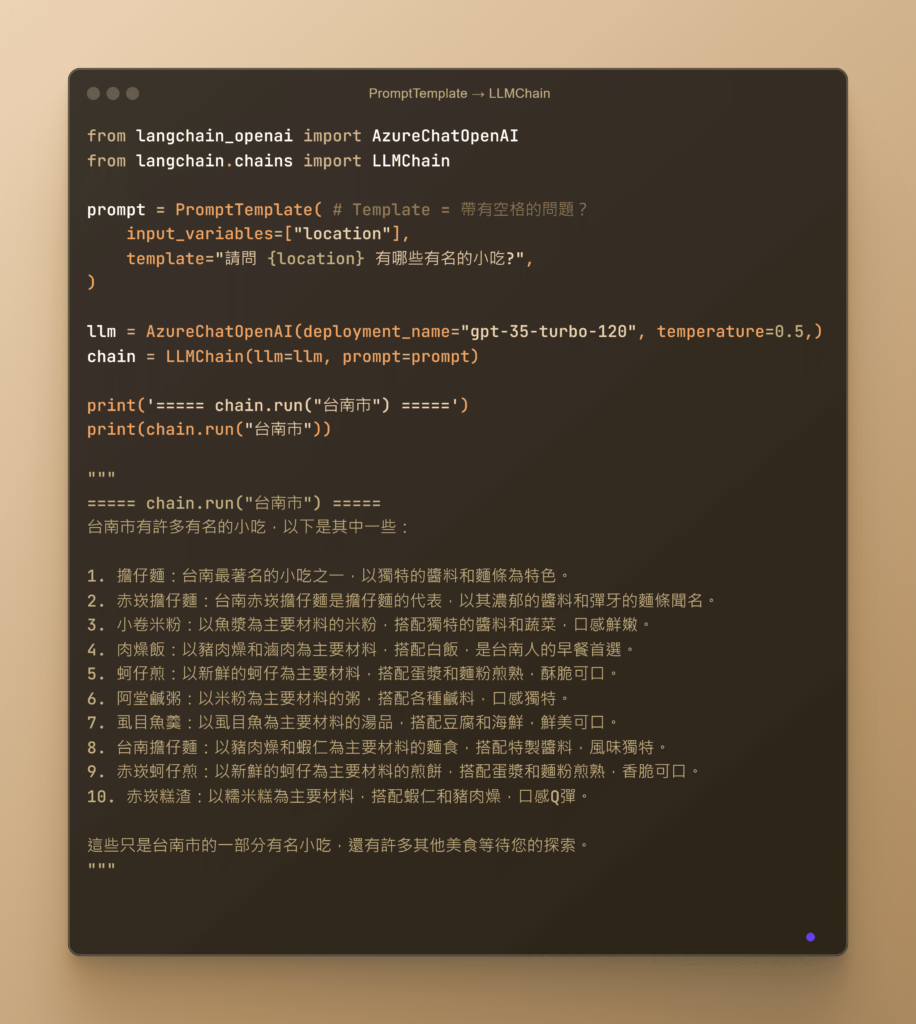
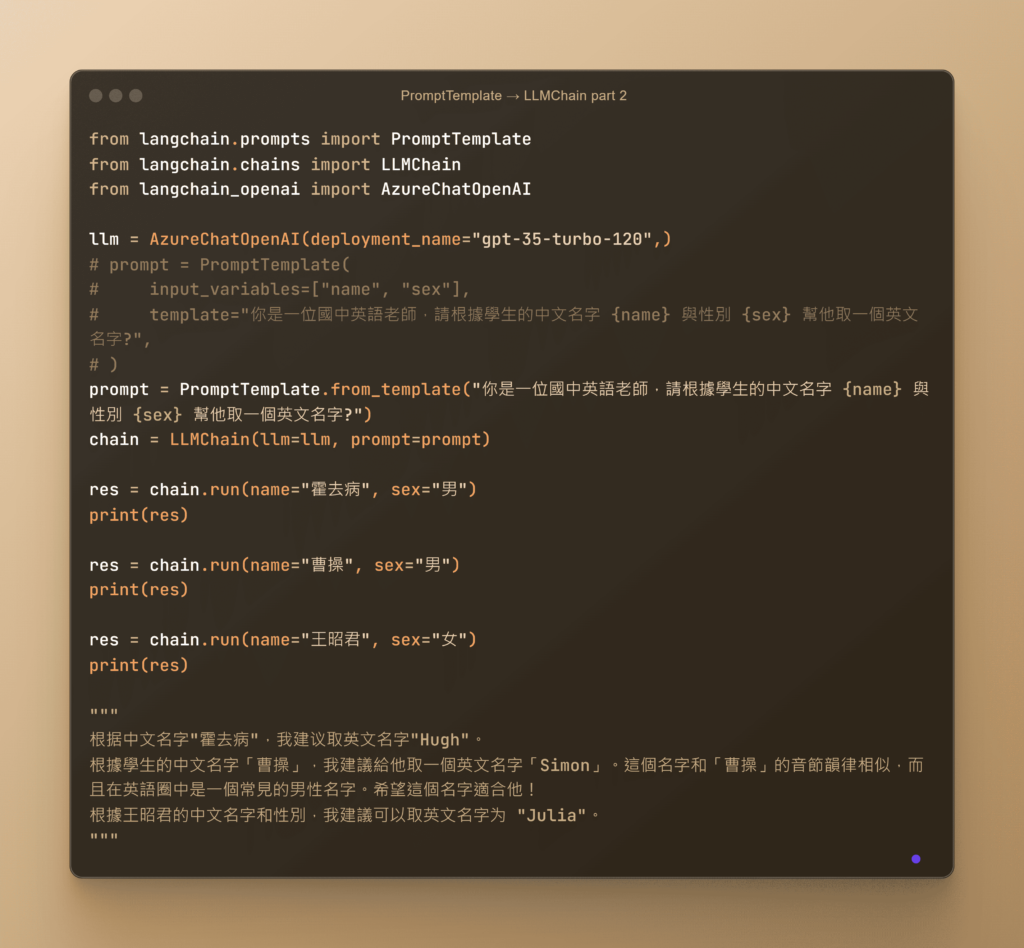
當我們談到 LLMChain 時,它是 LangChain 中的一個關鍵組件,具有強大的功能和靈活性。這個組件的主要作用是將提示模板(Prompt Template)和語言模型(Language Model)結合在一起,處理輸入和輸出,並確保每次調用模型時都遵循預先定義的提示模板。這樣的設計使得 LLMChain 成為構建高效和一致的語言處理應用的核心。
應用與優勢
模塊化設計: LLMChain 的模塊化設計允許開發者將不同的模型和提示模板靈活地組合在一起。這意味著您可以針對不同的應用場景,快速調整和優化您的模型和模板配置,從而提高開發效率和應用性能。
高效處理: LLMChain 通過預定義的模板確保每次調用模型時的輸入和輸出一致,這不僅提高了處理效率,還減少了出錯的可能性。這對於需要高精度和高可靠性的應用場景尤為重要。
易於維護: 模塊化設計使得 LLMChain 更易於維護和擴展。您可以根據需求,隨時更新或替換提示模板或語言模型,而不需要大規模修改現有代碼。這種靈活性使得 LLMChain 在快速變化的技術環境中,依然能夠保持高效和穩定。
個性化體驗: 通過 LLMChain,您可以根據不同的用戶需求和行為,靈活生成個性化的提示。這使得應用能夠提供更貼近用戶需求的體驗,從而提高用戶滿意度和參與度。
多場景應用: LLMChain 可以廣泛應用於各種場景,包括但不限於聊天機器人、智能客服、內容生成、教育輔助工具等。它的靈活性和高效性使其能夠適應各種複雜的應用需求。
實例應用: 例如,在智能客服系統中,LLMChain 可以根據不同的客戶問題,自動選擇合適的提示模板和語言模型,快速提供準確的回答。這不僅提高了客服效率,還提升了用戶體驗。
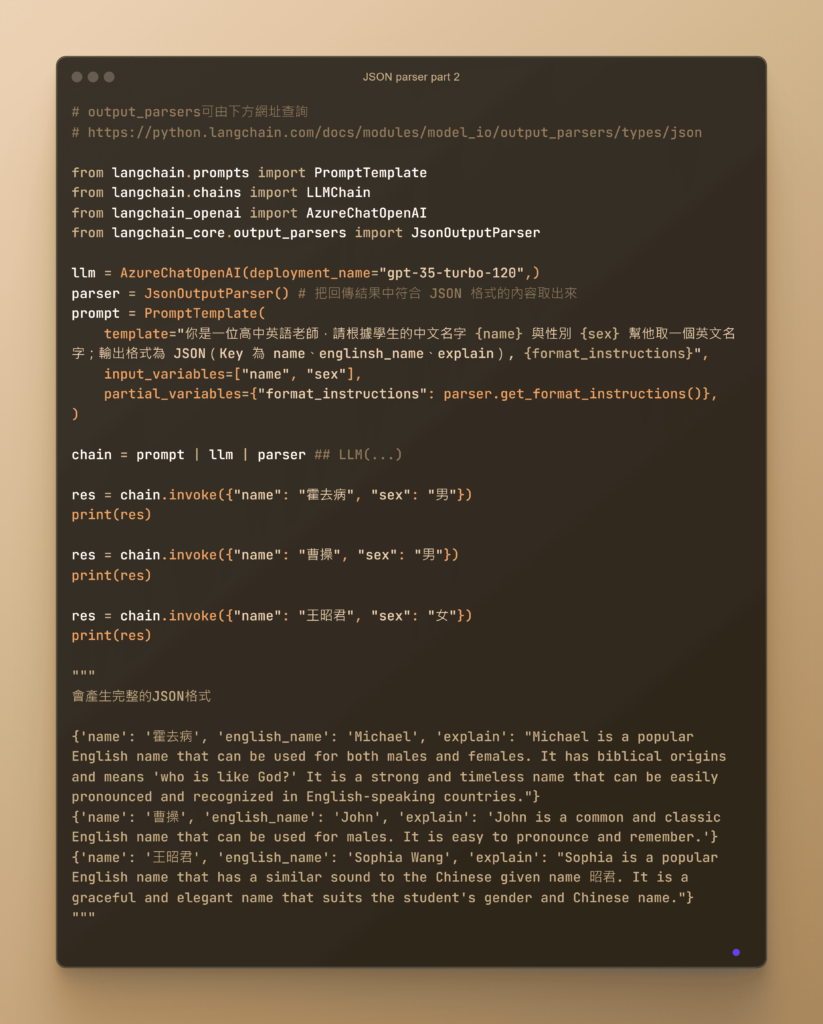
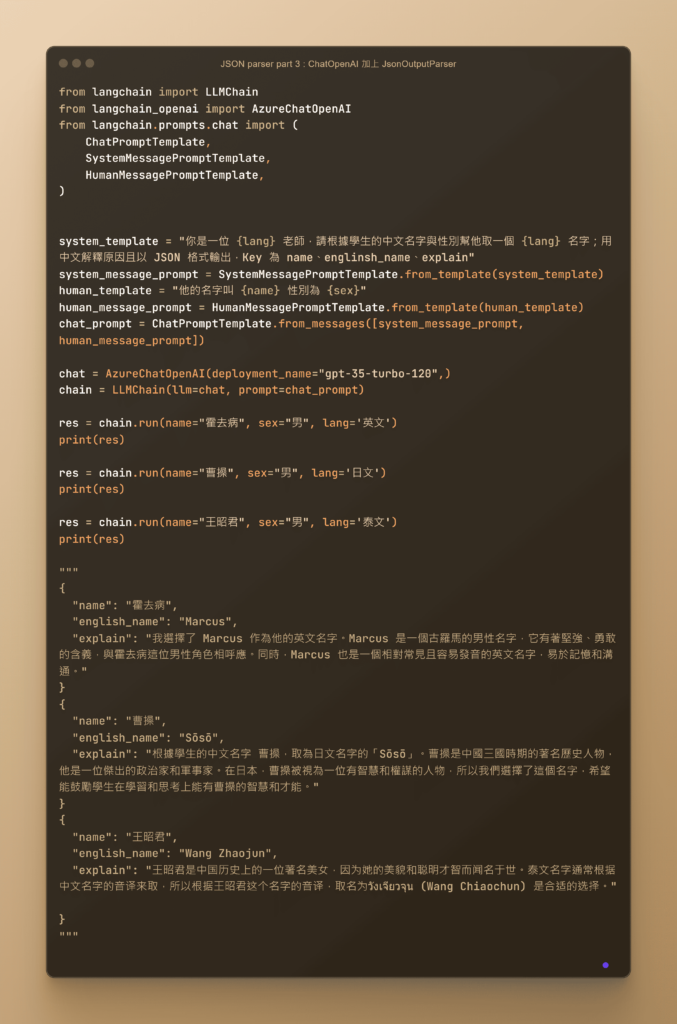
各種文件格式的 OutputParser 如JsonOutputParser
OutputParser 是 LangChain 中的重要工具之一,它負責解析模型輸出,確保數據符合預期格式並便於後續處理。這種工具極大地增強了應用程序的靈活性和可靠性。
應用與優勢
自定義解析器: OutputParser 的一大優勢在於其高度的可定制性。開發者可以根據特定需求創建自定義的 OutputParser,來處理各種格式的輸出數據。例如,您可以創建一個 XML 解析器來處理以 XML 格式返回的數據,或者創建一個 CSV 解析器來處理逗號分隔的數據。這種靈活性使得 OutputParser 能夠適應不同應用場景的需求。
數據驗證: OutputParser 不僅僅是解析數據,還能進行數據驗證。這意味著在解析數據的過程中,它可以檢查數據的完整性和一致性,確保數據符合預期的格式和結構。例如,JsonOutputParser 可以驗證 JSON 數據的結構是否正確,是否包含所需的字段,以及數據類型是否匹配。這有助於及時發現和糾正數據問題,提升應用的穩定性和可靠性。
多格式支持: OutputParser 可以支持多種不同的數據格式,如 JSON、XML、CSV 等。這使得應用程序能夠處理和整合來自不同來源的數據,提升數據處理的靈活性。例如,您可以同時處理來自 API 的 JSON 數據和來自數據庫的 CSV 數據,並將它們統一解析為應用程序所需的格式。
高效數據處理: 通過使用 OutputParser,您可以顯著提高數據處理的效率。預定義的解析器能夠快速解析數據,減少了手動處理數據的工作量和出錯的風險。此外,自定義解析器可以針對特定應用場景進行優化,進一步提升數據處理的速度和準確性。
實例應用: 在現實應用中,OutputParser 可以廣泛應用於各種場景。例如,在電子商務平台中,您可以使用 JsonOutputParser 解析來自不同供應商的產品數據,並將其轉換為統一格式,方便後續的數據整合和分析。在醫療領域,您可以使用 XML 解析器處理來自不同醫療設備的數據,確保數據的準確性和一致性,提升診斷和治療的效率。

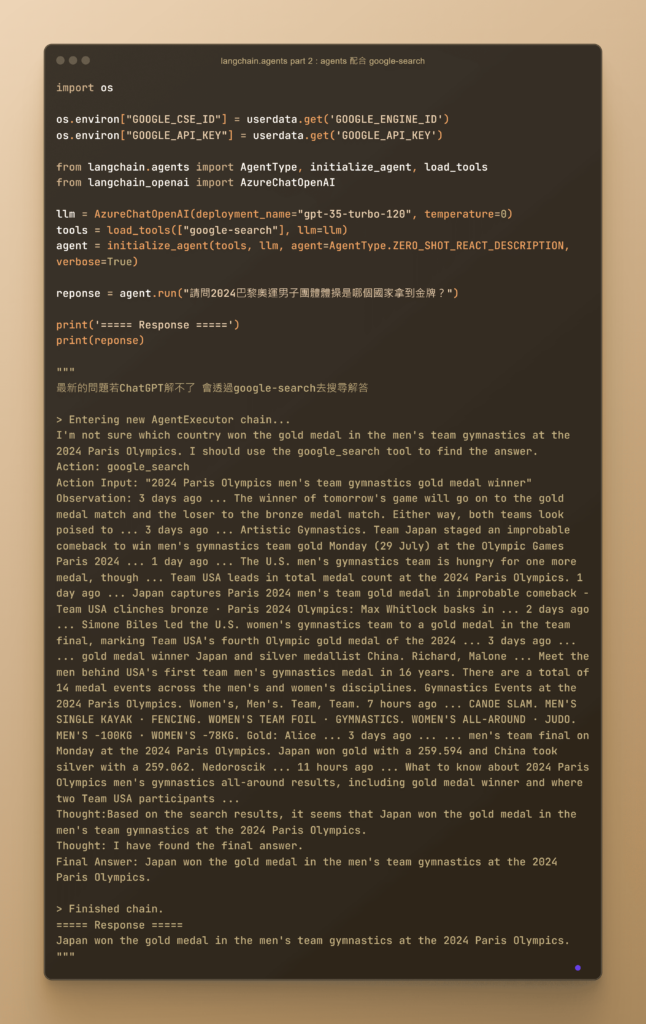
Agent
Agent 是 LangChain 中的一個強大功能,允許模型與外部工具和服務進行互動。這使得模型不僅僅是一個被動的語言處理工具,更是一個能夠主動執行任務和做出決策的智能系統。Agent 可以加載和使用多種工具,從而增強模型的能力和功能。
應用與優勢
多工具集成: Agent 的一個重要優勢是其多工具集成能力。這意味著模型可以同時使用多種外部工具來完成複雜的任務。例如:
- 搜索引擎: Agent 可以利用搜索引擎來查找最新的資訊,回答用戶的問題。這對於需要實時資訊的應用非常有用。
- 計算器: Agent 可以調用計算器來執行數學運算,提供精確的計算結果,這對於需要數據處理和分析的應用非常有幫助。
- 數據庫查詢: Agent 可以訪問和查詢數據庫,獲取和處理大量數據,這對於需要數據驅動決策的應用非常重要。
這種多工具集成能力,使得 Agent 能夠處理更廣泛和更複雜的任務,提高了模型的適用性和實用性。
智能決策: 通過 Agent,模型可以根據上下文和需求進行智能決策,選擇合適的工具來回答問題或執行任務。例如:
- 根據用戶問題選擇工具: 如果用戶問了一個需要實時資訊的問題,Agent 可以自動選擇搜索引擎來查找答案。如果用戶需要計算某個數值,Agent 可以調用計算器來完成。
- 上下文感知: Agent 能夠理解對話的上下文,根據前後信息做出更準確的判斷和決策。例如,在與用戶的多輪對話中,Agent 可以記住用戶之前提到的需求和偏好,提供更符合用戶期望的答案。
這種智能決策能力,使得 Agent 能夠提供更準確、更個性化的服務,提升用戶體驗。
增強模型功能: Agent 的多工具集成和智能決策能力,大大增強了模型的功能。這意味著模型不僅僅能夠回答問題,還能夠主動執行各種任務,從而提升了整體應用的效率和效果。例如:
- 自動化工作流程: Agent 可以自動執行一系列操作,例如從數據庫查詢數據,然後進行計算,最後將結果返回給用戶,這樣可以節省大量人力和時間。
- 多任務處理: Agent 可以同時處理多個任務,例如一邊回答用戶的問題,一邊查詢數據庫,提供更高效的服務。
ConversationChain
ConversationChain 是 LangChain 中的一個重要組件,用於管理和維護對話上下文,確保模型在多輪對話中能夠保持上下文記憶。這對於需要連貫對話和上下文理解的應用非常重要。
應用與優勢
記憶管理: ConversationChain 的記憶管理功能使得模型能夠記住對話中的關鍵訊息,從而提供更準確和一致的回應。這意味著:
- 上下文持續性: 模型能夠記住之前的對話內容,不會因為單獨的對話輪次而忘記關鍵信息。例如,在客服應用中,模型能夠記住客戶之前的問題和需求,提供更連貫的解答。
- 個性化體驗: 通過記住用戶的偏好和歷史對話,模型能夠提供更個性化的回應,提升用戶體驗。例如,模型可以根據用戶之前的選擇推薦相似的產品或服務。
多輪對話策略: ConversationChain 支持設計和實現多輪對話策略,確保對話的自然流暢和邏輯連貫。這包括:
- 主題追蹤: 模型能夠追蹤對話中的主題變化,根據上下文做出適當的回應。例如,當用戶從詢問產品信息轉向詢問購買流程時,模型能夠自動調整回應內容。
- 糾錯與補充: 在對話過程中,模型能夠識別並糾正錯誤信息,或在必要時提供補充說明,確保對話的準確性和完整性。
增強用戶互動: ConversationChain 通過保持對話上下文記憶,增強了模型與用戶之間的互動性。這意味著:
- 持續對話: 模型能夠與用戶進行持續的、多輪次的對話,而不會因為上下文丟失而中斷。這對於需要長時間互動的應用場景非常有用。
- 情感理解: 通過記住用戶的語氣和情感表達,模型能夠更好地理解用戶的情感狀態,提供更具同理心的回應。
